初步了解强化学习
初识强化学习的人一般都会见到下面这张图:
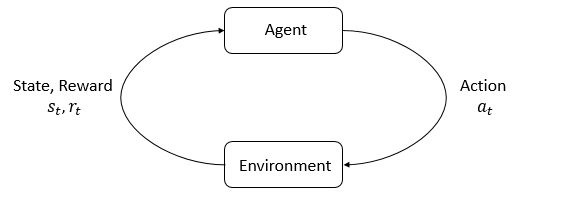
强化学习的基本设想是一个智能体(agent)与环境(environment)交互,当智能体采取一个动作(action)后,环境的状态(state)会发生一个改变,并且会对智能体反馈一个奖励(reward)来评价这个动作。
举个例子:

相信这款类似的游戏大家都玩过,智能体就是小鸟,不做任何操作小鸟会向前和下降,环境就是小鸟所处的游戏环境,小鸟向上和不向上就是它的动作,假如它没有死亡,奖励设置为1,死亡奖励设置为-1000。直观上理解,强化学习通过小鸟一次又一次的尝试游戏,根据奖励更改自己的行为方式。
强化学习的基本假设: 所有的目标都是最大化智能体获得的累计奖励。
强化学习概念理解及标注符号
动作: $a$表示智能体采取的一个动作。
动作空间: $A$表示智能体可以采取的所有的动作集合,有限集。
状态: 状态有环境的状态和智能体的观测状态之分。环境的状态能表示所处环境的所有信息,而智能体的观测状态只包括智能体可以观测的信息。理论上我们需要的状态是环境状态,但是智能体获取的是观测状态,而环境的有些信息可能是无法观测的。这时候我们通过构建合适的描述可以让观测状态近似环境状态,所以实际操作过程中常用$s$(智能体观测状态)代表环境状态。
状态空间: $S$表示所有可能状态的集合,有限集。
轨迹: $<s_0,a_0,s_1,a_1,…>$是一个智能体与环境相对于时间的交互序列,称它为一个轨迹(episode),记为$\tau$。对于上面的小鸟游戏来讲,一局游戏便会产生一个轨迹。
策略:
智能体会只根据当前状态,不考虑历史状态选取一个动作,那么如何选取这个动作被称为策略(policy),记为$\pi$。策略有两种,决定性策略和统计性策略。决定性策略就是根据当前状态$s$定死将要采取的动作$a$,表示为$a = \pi(s)$。而统计行策略是对$a$施加一个概率分布,表示为 $a \sim \pi(\cdot |s)$。
奖励: 奖励有即时奖励(reward)和累积奖励(return,又称为回报)之分。顾名思义,即时奖励就是每执行完一次动作,当前行为返回的奖励,记为$r$。累积奖励就是这些即时奖励之和,记为$R$。
累积折扣回报: 有个折扣系数$\gamma(\gamma \in [0,1])$。具体表现形式为 $$R_t = r_{t+1}+\gamma r_{t+2}+\gamma^{2}r_{t+3}+…$$ 直观上理解是后面的奖励要变小,举个例子,RMB随着时间越来越不值钱。数学上保证$R$的收敛性。
以上概念理解是很重要的!!!只有理解这些概念后面才能更好的学习RL算法和数学推导。
马尔可夫性
假设目前有一系列状态$<s0,s1,s2,…>$,对于$s_{t+1}$,如果$s_{t+1}$只与$s_t$有关,与之前的历史状态无关,那么我们称$s_t$具备马尔可夫性。表示为$P(s_{t+1}|s_t)=P(s_{t+1}|s_1,s_2,…s_t)$
马尔可夫过程
对于上述状态序列,在每个时刻$t$,$s_t$都有马尔可夫性,则称这个随机过程为马尔可夫过程。对于一个马尔可夫过程,我们只需要$<S,P>$描述。其中$S$是状态空间,$P$是状态转移概率矩阵。$P_{i,j}$表示$S_i$转换为$S_j$的概率。如下图:
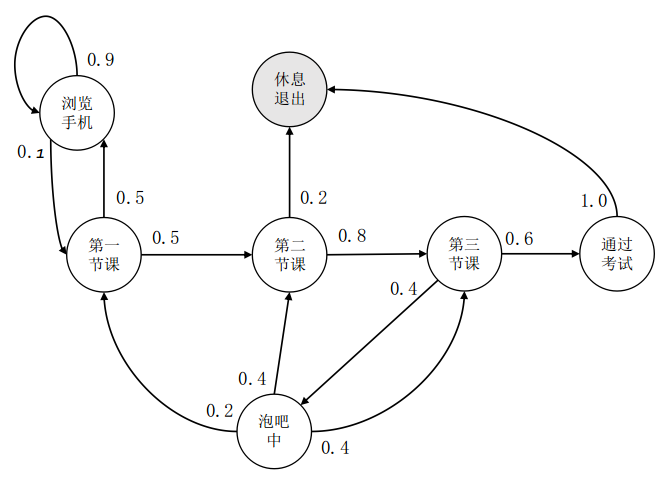
节点表示状态,边上的权重表示状态转移概率。
马尔可夫奖励过程
对于一个马尔可夫过程,如果状态之间的每次转移都会获取一个奖励,我们称其为马尔可夫奖励过程(MRP)。此时有一个奖励函数$r$,表明每个状态转换的即时奖励。所以一个MRP一般由$<S,P,r,\gamma>$决定。如下图:
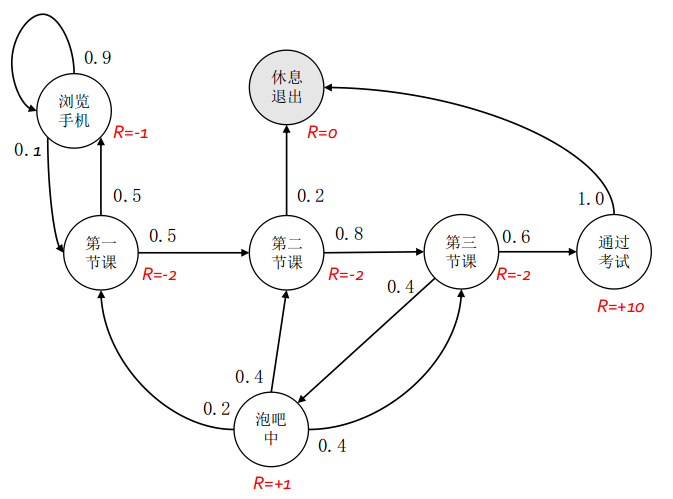
每次状态转换之间多一个奖励值,这个奖励值是由环境决定的。
马尔可夫决策过程
在MRP上加上动作后就会产生马尔可夫决策过程(MDP),此时状态转移是从当前状态执行某个动作后再转到下一个状态。所以一个MDP由$<S,A,P,r,\gamma>$决定。如下图:
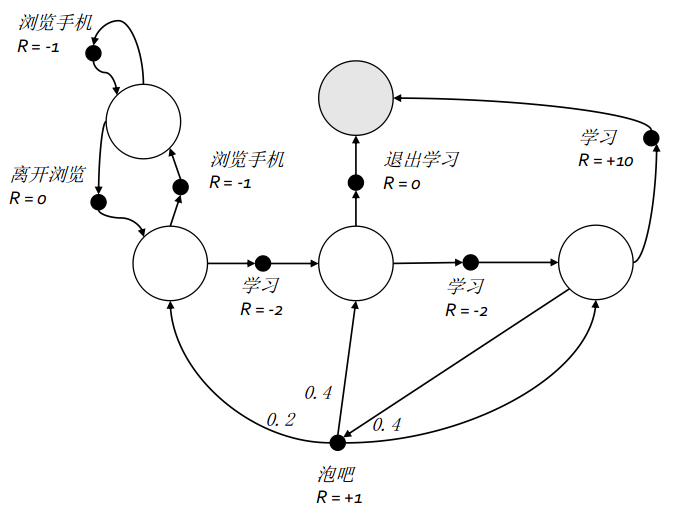
值函数和贝尔曼方程
强化学习就是用的MDP,可能现在还不是很理解MDP有什么用,现在我们将它用到强化学习中进行一波推导。
首先我们用记号$<s_0,a_0,s_1,a_1,…>$表示一个轨迹,回想一下RL的目标,找到能够获得最大回报的策略。那么我们假设初始状态是$s_0$,那么就会产生很多条路径$\tau$,对于每一个$\tau$,我们都可以计算出相对应的回报,那么问题来了,这么多条路径有这么多个回报我们具体用那个回报作为我们的目标优化值呢?这里有个很常见的手段,用他们的期望值,并且称为价值(value)。正常思路求期望值是直接找到$\tau$的分布,然后用定义法求出。这样计算一方面太复杂了,还有就是途径可能没办法结束,这样没办法直接计算。于是人们想到了利用动态规划的思想计算,也就是贝尔曼方程。
首先定义$v(s)=E[R_t|s_t=s]$,即确定初始状态后回报的期望值。 注意:$v$只是$s$的函数,定义式中的$t$是表明计算所有从状态$s$起始于任意时刻$t$的轨迹的期望
再定义$q(s,a)=E[R_t|s_t=s,a_t=a]$,即确定初始状态和执行动作后回报的期望值。 同样注意时间的问题。
下面先推导一条纯数学公式,假设有一个马尔可夫过程$<X,Y,Z>$,$D_y$表示$Y$的所有可能取值,$D_z$表示$Z$的所有可能取值,那么有以下结论: $$E[Z|X=x]=\sum_{y \in D_y}P(Y=y|X=x)\cdot E[Z|Y=y]$$
$$E[Z|X=x]=\sum_{z \in D_z}z \cdot P(Z=z|X=x) \\ =\sum_{z \in D_z}z \cdot (\sum_{y \in D_y}P(Z=z|Y=y) \cdot P(Y=y|X=x)) \\ =\sum_{y \in D_y}P(Y=y|X=x)(\sum_{z \in D_z}z \cdot P(Z=z|Y=y)) \\ =\sum_{y_ \in D_y}P(Y=y|X=x) \cdot E[Z|Y=y]$$
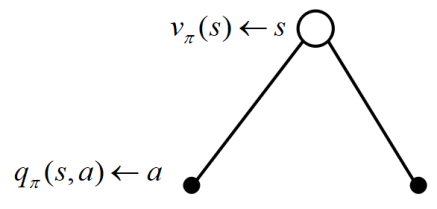
根据上图,我们根据同样推算数学结论的方式有: $$v(s)=E[R_t|s_t=s]=\sum_{a \in A} \pi(a|s) \cdot E[R_t|s_t=s,a_t=a]=\sum_{a \in A} \pi(a|s) \cdot q(s,a)(1)$$
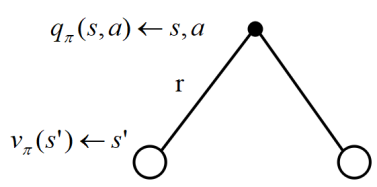
根据上图,同样的推导方式,有
记$r_s^a=E[r_{t+1} | s_t=s,a_t=a]$,表示只与状态和执行动作有关的即时奖励函数。
则有 $$q(s,a)=r_s^a+\gamma \sum_{s’ \in S}P(s_{t+1}=s’|s_t=s,a_t=a)\cdot v(s’) (2)$$
由(1)(2): $$v(s)=\sum_{a \in A} \pi(a|s) \cdot (r_s^a+\gamma \sum_{s’ \in S}P(s_{t+1}=s’|s_t=s,a_t=a)\cdot v(s’))$$ $$q(s,a)=r_s^a+\gamma \sum_{s’ \in S}P(s_{t+1}=s’|s_t=s,a_t=a)\cdot (\sum_{a’ \in A} \pi(a’|s’) \cdot q(s’,a’))$$
注意,当环境确定奖励函数后,每个策略$\pi$都对应一个价值函数。后续~